 English
EnglishPerformance and availability monitoring in levels
The availability of an IT component can be obtained by measuring (monitoring) the performance of that component. If the performance is below a certain threshold, the IT components is reported unavailable.
Monitoring IT systems can be done using a variety of tools. Vendors like IBM, HP, BMC and others provide tools to:
- Measure performance
- Capture logging
- Generating alarms based on thresholds
- Report the collected data in dashboards or other overviews
Typically, the number of measuring points in an IT landscape is quite overwhelming. When installed out of the box, monitoring tools will typically detect many issues per second, leading to many false alarms. Therefore, it is essential to tune the monitoring system to only generate useful alarms and to create reports containing useful information for specific stakeholders.
Performance measurement (and as derivate – availability detection) can be done on multiple levels:
- Business process level
- Application component level
- Infrastructure component level
It is important to have separated performance measurements on all three levels and to have processes to solve issues on all individual levels.
For the end user of the system, only the business process level is important – as soon as the performance of this level is too low, the end users will be in trouble. Therefore, the business process level should be measured. Today’s tools are able to measure individual business process steps either by measuring their normal use or by measuring the effect of generated business actions. For instance, it can be measured how long it takes to print an invoice and it can be measured how long a simulated fake order takes to be processed in a certain business step.
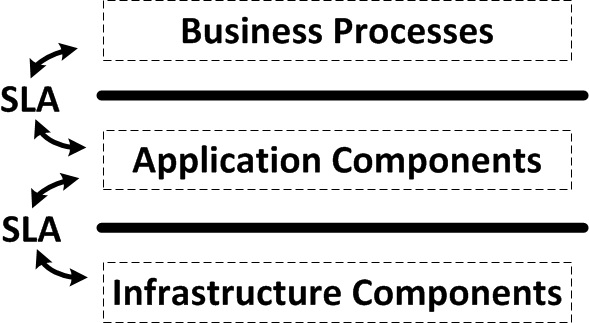
If the performance on the business process level is below the set threshold, first the performance of the underlying application component(s) should be verified. Since every layer is responsible for its own performance, it could be that there is a problem in the application component layer causing the performance issue in the business process layer. And the application component layer could have performance issues due to a performance issue in the infrastructure component layer. Therefore it is important to separate these layers and give systems managers specific responsibilities for a certain layer. Between the layers, service level agreements should be agreed (Service Level Agreements – SLAs).
If the performance of the business process level is too low and there is no problem in the underlying application components, the solution to the performance issue must be found in the business process layer itself. If this is not the case, then there is a mismatch between the layers – a certain business process issue is apparently not detected in the lower application service layer.
Of course, this reasoning is also valid for the relation between the application components layer and the infrastructure component layer.
On the application component level, performance can be measured effectively if the application components contains “hooks” that the monitoring tool can use to verify the performance of a software component. Without these hooks, measuring can only be done on a much lower granularity. Especially when bespoke software is developed it is advised to invest in building these hooks in the software as part of the regular development process. Typical measurements are the number of times a (part of an) application component is used and how long it takes to finish a certain task. In software, typically there are some hot spots – parts of the code that are used much more frequently than others. By measuring using hooks in the software, these hot spots can be found, monitored, and optimized for performance.
On the infrastructure component level, the performance of each individual component can be measured. Examples are:
- CPU load
- Memory usage
- Network response time
- Network load
- Storage response time
- Storage load
Based on these measurements, low performance, or even unavailability of a certain component or a set of components can be detected.
Systems managers can react on the detection of low performance by addressing the issue at hand. It is important to acknowledge that early detection and resolving of performance issues is essential to avoid performance problems at the higher layers. Early detection and resolving keeps the systems managers busy, but reduces the risk that end users experience performance issues.
It is like the people who work hard to keep the trains running on time. If they do their work well, no one will notice…
This entry was posted on Friday 09 January 2015