A Quantum computer is a computer based on quantum mechanics. Quantum mechanics is a scientific theory that explains how tiny particles like atoms and electrons behave and interact with each other. Quantum mechanics deals with very small particles and operates on principles like probability and uncertainty.
A quantum computer does not use classical CPUs or GPUs, but a processor based on so-called qubits. A qubit (or quantum bit) is the basic unit of quantum information. Unlike classical bits, which can be either 0 or 1, qubits can exist in a superposition of states, representing multiple values simultaneously. This property enables quantum computers to perform certain tasks much faster than classical computers.
The number of qubits in a quantum computer is not comparable to the number of transistors in a CPU. The idea behind a quantum computer is that instead of calculating all the possibilities of a problem, a quantum computer can determine all the solutions at once. A problem with 1 billion possibilities can be computed with 30 qubits at once.
But computing is not the right word. Traditional computers are deterministic and quantum computers are probabilistic. Deterministic means that the result is predetermined, and every time a calculation is performed, the answer will be the same. Probabilistic means that there is a high probability that the result is correct, but that each computation is an approximation that may produce a different result each time. Because of the uncertainty inherent in quantum mechanics by definition, the answer is always an approximation.
Qubits are also highly unstable - they must be cooled to near absolute zero to become superconducting, and they can only hold a stable position for a few milliseconds. This means that calculations have to be repeated many times to get a sufficiently reliable answer.
Quantum computers are still in the experimental stage. A few research centers and large companies like IBM are working on them. Given the complexity and cooling requirements, quantum computing capabilities will most likely be offered as a cloud service in the future.
Quantum computing can be used in medicine, for example, it could speed up drug discovery and help medical research by speeding up chemical reactions or protein folding simulations, something that will never be possible with classical computers because it would take thousands of years to calculate on a classical supercomputer.
Because of its properties, quantum computing could easily break current encryption systems. Therefore, cryptographers are working on post-quantum algorithms.
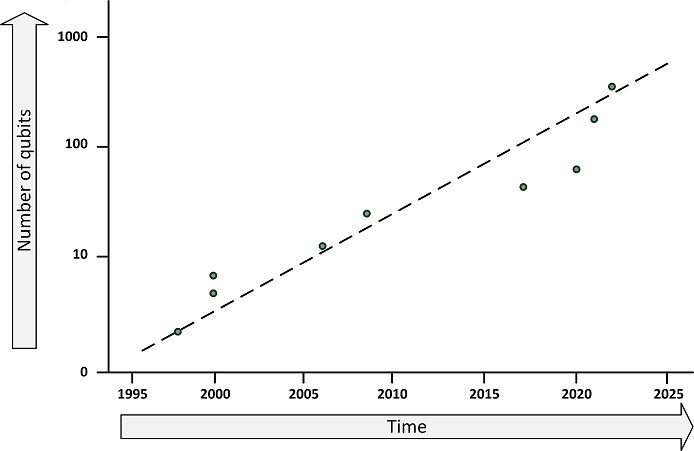
IBM has built the largest quantum computer yet, with 433 qubits. This figure shows the progression of the number of qubits in the largest quantum computers.
This entry was posted on Donderdag 20 April 2023
|
|
................
|
.
.
.
The book's previous edition
was rewarded

|
The 4th edition of my book on Infrastructure Architecture called "Infrastructure Architecture - Infrastructure Building Blocks and Concepts" is published.
Download the Table of Contents.
A preview of the book can be downloaded here.
How to order
Paperback (480 pages) - ISBN 978-1-4477-8560-6
eBook - ISBN 978-1-4477-8093-9
- From Amazon.com the book can be ordered as a Kindle ebook.
- From the Apple bookstore (for Mac or iOS devices, like the iPad) - search for Sjaak Laan in the Books app on your device.
- The ebook is also available on the Kobo bookstore.
Abstract
IT infrastructure has been the foundation for successful application deployments for many decades. However, general and up-to-date infrastructure knowledge is not widespread. Experience shows that software developers, system administrators, and project managers often have little understanding of the major impact that IT infrastructure has on the performance, availability, and security of software applications.
This book explains the concepts, history, and implementation of IT infrastructure. Although there are many books on each of the infrastructure building blocks, this is the first book to describe them all: datacenters, servers, networks, storage, operating systems, and end-user devices.
The building blocks described in this book provide functionality, but they also provide the non-functional attributes of performance, availability, and security. These attributes are discussed at a conceptual level in separate chapters and in more detail in the chapters on each building block.
Whether you need an introduction to infrastructure technologies, a refresher course, or a study guide for a computer science class, you will find that the building blocks and concepts presented provide a solid foundation for understanding the complexities of today's IT infrastructures.
This book can be used as a course book - it is used by a number of universities worldwide as part of their IT courses based on the IS 2020.3 curriculum.
Note to the 4th Edition
In the fourth edition of this book, a number of corrections have been made, some terminology has been clarified, and several typographical and syntax errors have been corrected. In addition, the following changes have been made:
- The content has been updated to reflect the new Association for Computing Machinery (ACM) IS 2020.3 Curriculum - Competency Area - IT Infrastructure.
- A new chapter on cloud computing has been added, and cloud-related content has been added throughout the rest of the book.
- A new chapter on documenting infrastructures was added.
- New technologies such as serverless computing, edge computing and quantum computing have been added.
- The security chapter has been rewritten and restructured to better reflect infrastructure-related security concerns.
- The Infrastructure as Code chapter has been rewritten to reflect current working practices and a chapter on automation has been added as this has become more important over the years.
- The chapter on Purchasing Infrastructure and Services has been removed as it was too general and not specific to infrastructure. The chapter was mandatory for the IS 2010.4 syllabus, but has been removed from the IS 2020.3 syllabus.
- The networking chapter has been expanded to include POP, SMTP, FTP, HTTP, and HTTPS protocols. This is a requirement from the IS 2020.3 syllabus.
- An appendix has been added that describes a high-level checklist that can be used to ask the right questions when learning about an existing infrastructure in the field.
- More than 100 edits were made throughout the book to clarify and update content, and to remove outdated content.
- Finally, as technology has advanced in recent years, the book has been updated to include the most current information.
Course Material
The book is used in a number of universities in the USA, Australia, Chile, and Kuwait, as study material for their IT infrastructure courses. The book is especially suited for courses based on the IS 2020.3 curriculum. A reference matrix of the IS 2020.3 curriculum topics (as used in many universities in the USA) and the relevant sections in this book is provided in the appendix.
Based on requests from university professors, I created a set of course materials. It contains all pictures used in the book in both Visio and high-resolution PNG format, the list of abbreviations, a PowerPoint slide deck for each chapter (> 700 slides in total), and a set of test questions per chapter (> 200 questions in total).
The course materials can be downloaded here.
Please read the course setup in the Excel sheet "Course setup".
There is a set of multiple choice questions available for professors / lecturers. Please contact the author (sjaak.laan@gmail.com) with your name, position and university name to request a copy.
This entry was posted on Maandag 03 April 2023
In het AG-Connect artikel “Witte Huis wil clouds van Microsoft, Google, AWS, Oracle betere beveiliging opleggen” wordt op basis van een artikel van de website Politico gesteld dat grote cloudproviders, zoals Amazon AWS, Microsoft Azure en Google GCP too big to fail zijn en dat de Amerikaanse overheid de security van cloudproviders wil gaan reguleren.
De afgelopen jaren hebben veel organisaties hun IT-systemen gemigreerd naar grote cloudproviders. Hierdoor zou het omvallen van deze cloudproviders – en het daarmee uitvallen van een scala aan IT-diensten van overheden en bedrijven – een enorme schade veroorzaken. Een schade vergelijkbaar, of zelfs groter, dan die van de too big to fail-banken.
Een terechte zorg. De vraag is echter hoe dit risico beheerst kan worden. Het artikel op Politico stelt dat cloudservers niet zo veilig zijn gebleken als regeringsfunctionarissen hadden gehoopt. Onduidelijk is waaruit dit blijkt en wat de verwachtingen waren. Ook is het onduidelijk of het alternatief, het weer in eigen beheer nemen van de eigen IT-voorzieningen, tot hogere veiligheid zou leiden.
Ik durf dat wel te betwijfelen. Ter vergelijking: bij banken wordt ook soms geld ontvreemd door criminelen. Maar is het dan beter om je geld thuis in je matras te bewaren? Gezien de staat van IT-systemen bij de overheid zou ik verwachten dat de IT en security bij de cloudleveranciers veel beter op orde is.
Dat hackers uit landen als Rusland cloudservers van bedrijven als Amazon en Microsoft gebruiken als springplank voor aanvallen op andere doelwitten is niets nieuws en heeft met bovenstaande weinig te maken. Als platform voor aanvallen is de cloud zeer geschikt. Maar dat staat los van waar de doelwitten zich bevinden.
This entry was posted on Vrijdag 17 Maart 2023
In het in augustus 2022 aangenomen Rijkscloudbeleid staat dat er geen belemmering meer is om overheidsdata onder voorwaarden onder te brengen bij Amerikaanse cloudleveranciers. Hierbij moet de data wel op fysieke opslagsystemen in Europa worden opgeslagen en in Europa worden bewerkt. In de tweede kamer is op 21 februari 2023 een motie aangenomen om bij de komende evaluatie van het Rijksbrede cloudbeleid, eind 2023, de doorgifte van persoonsgegeven en overheidsdata buiten de EU te heroverwegen en de keuze te laten vallen op een Europees cloud-initiatief. “Overheidsdiensten moeten straks gebruikmaken van Europese clouddiensten.” schrijft Computable.
De vraag om geen overheidsdata op te slaan bij buitenlandse partijen is begrijpelijk, maar het getuigt ook van weinig inzicht in de huidige marktsituatie. Van de top 5 grootste cloudleveranciers zijn er 4 Amerikaanse en 1 Chinese partij. Uiteraard zijn er ook veel kleinere partijen actief, ook in Europa, maar deze hebben niet de slagkracht en het innovatievermogen om serieus te concurreren met de grote leveranciers. En het profiteren van de innovaties van cloudleveranciers is een van de belangrijkste redenen voor de overheid om gebruik te maken van clouddiensten. Basisclouddiensten, zoals servers en opslag kunnen veel partijen bieden. Maar als het om geavanceerde diensten gaat als Artificial Intelligence (AI) of Machine Learning, doen de kleinere cloudaanbieders niet serieus mee.
Staatssecretaris Alexandra van Huffelen (Digitalisering) geeft aan dat de federatieve cloudstructuur Gaia-X nog niet groot genoeg is om een daadwerkelijk alternatief te bieden. Ik zou het sterker formuleren: Gaia-X is helemaal geen cloudleverancier en dus ook geen partij in deze discussie. Gaia-X is slechts een set afspraken om data-uitwisseling tussen cloudleveranciers eenvoudiger en veiliger te maken, zodat deze voldoet aan Europese privacy regels. Gaia-X bouwt helemaal geen datacenters.
Er zijn een aantal opkomende cloudleveranciers in Europa, zoals IONOS in Duitsland en OVHcloud in Frankrijk, die een soevereine cloud aanbieden. Ook zien we initiatieven van de Amerikaanse cloudleveranciers om in Europe een losstaande soevereine cloud te bouwen, vaak in samenwerking met Europese partijen. Het gaat nog wel even duren voor al deze initiatieven een volwaardige tegenhanger zijn voor de bestaande Amerikaanse cloudleveranciers. Intussen wordt in overheidsland al druk gebouwd aan toepassingen bij de Amerikaanse cloudleveranciers.
This entry was posted on Vrijdag 10 Maart 2023
Van veel Nederlandse studenten staan de persoons- en studiegegevens opgeslagen in datacentra van Amerikaanse techbedrijven. Volgens het kabinet zijn er maatregelen genomen om lekken te voorkomen. “Experts waarschuwen voor de risico’s van cloudopslag. De techbedrijven die erachter zitten, opereren onder de wetgeving van de VS” staat er in een artikel op Univers. “Zo hebben Amerikaanse opsporingsdiensten relatief gemakkelijk toegang tot de gegevens en kunnen die ook worden verkocht aan adverteerders,” schrijft het journalistieke medium van Tilburg University.
Dit is onjuist. Hierbij worden social media platforms en andere gratis diensten verward met betaalde clouddiensten van Azure en AWS. Het klopt dat Amerikaanse bedrijven vallen onder Amerikaanse wetgeving, en dat met de Amerikaanse CLOUD-act opsporingsdiensten in specifieke gevallen (zoals mogelijk terrorisme) data van één bepaald persoon mogen opeisen. Maar van grootschalige toegang tot gegevens, laat staan het verkopen daarvan is geen sprake. Overigens geldt ook voor andere landen dat er wetgeving is die opsporingsdiensten in het buitenland bepaalde bevoegdheden geven.
De Nederlandse overheid heeft met Microsoft aanvullende afspraken gemaakt over het gebruik van de diensten van Microsoft365, waarbij onder andere veel minder zogenaamde telemetriegegevens naar Microsoft worden gestuurd. Deze afspraken, gemaakt door Strategisch Leveranciers Management Rijk, worden nu ook gemaakt met andere cloudaanbieders, zoals AWS en Google. We zien dat Amerikaanse partijen zich de laatste tijd veel beter bewust worden van de verschillen in privacywetgeving en -beleving dan in de VS en dat ze zich daarop aan het aanpassen zijn. Dat is natuurlijk in hun eigen belang, maar ook van belang van de burgers in Nederland.
This entry was posted on Dinsdag 17 Januari 2023
 English
English