 English
EnglishBusiness Continuity Management (BCM) and Disaster Recovery Plan (DRP)
Although many measures can be taken to provide high availability, the availability of the IT infrastructure can never be guaranteed in all situations. In case of a disaster, the infrastructure could become unavailable, in some cases for a longer period of time. Business continuity is about identifying threats an organization faces and providing an effective response.
Business Continuity Management (BCM) and Disaster Recovery Planning (DRP) are processes to handle the effect of disasters. The Recovery Time Objective (RTO) and the Recovery Point Objective (RPO) determine the requirements for DRP.
Business Continuity Management (BCM)
BCM is not about IT alone. It includes managing business processes, and the availability of people and work places in disaster situations. It includes disaster recovery, business recovery, crisis management, incident management, emergency management, product recall, and contingency planning.
A Business Continuity Plan (BCP) describes the measures to be taken when a critical incident occurs in order to continue running critical operations, and to halt non-critical processes. The BS:25999 norm describes guidelines on how to implement BCM.
Disaster Recovery Planning (DRP)
Disaster recovery planning contains a set of measures to take in case of a disaster, when (parts of) the IT infrastructure must be accommodated in an alternative location. The IT disaster recovery standard BS:25777 can be used to implement DRP.
DRP assesses the risk of failing IT systems and provides solutions. A typical DRP solution is the use of fall-back facilities and having a Computer Emergency Response Team (CERT) in place. A CERT is usually a team of systems managers and senior management that decides how to handle a certain crisis once it becomes reality.
The steps that need to be taken to resolve a disaster highly depends on the type of disaster. It could be that the organization's building is damaged or destroyed (for instance in case of a fire), maybe even people got hurt or died.
One of the first worries is of course to save people. But after that, procedures must be followed to restore IT operations as soon as possible. A new (temporary) building might be needed, temporary staff might be needed, and new equipment must be installed or hired.
After that, steps must be taken to get the systems up and running again and to have the data restored. Connections to the outside world must be established (not only to the Internet, but also to business partners) and business processes must be initiated again.
RTO and RPO
Two important objectives of DRP are the Recovery Time Objective (RTO) and the Recovery Point Objective (RPO). The next figure shows the difference.
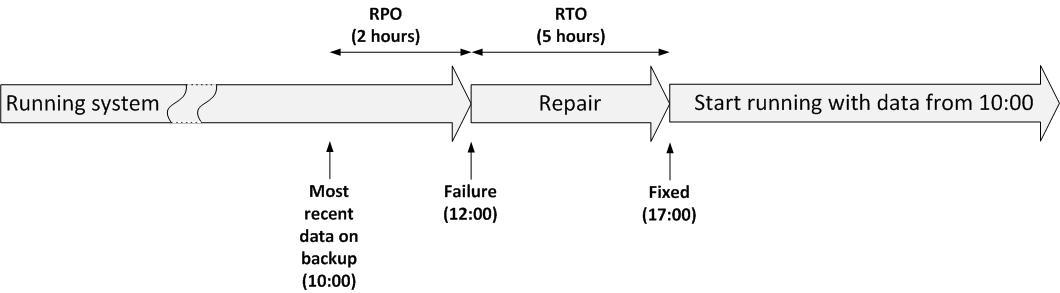
Figure: RTO and RPO
The RTO is the duration of time within which a business process must be restored after a disaster, in order to avoid unacceptable consequences (like bankruptcy). So the RTO determines the maximum time it may take for a failure to be repaired.
RTO is basically the same concept as MTTR, but for a complete business process instead of one component. Measures like failover and fall-back must be taken in order to fulfill the RTO requirements.
The RPO is the point in time to which data must be recovered considering some "acceptable loss" in a disaster situation. It describes the amount of data loss a business is willing to accept in case of a disaster, measured in time. For instance, when each day a backup is made of all data, and a disaster destroys all data, the maximum RPO is 24 hours – the maximum amount of data lost between the last backup and the occurrence of the disaster.
To lower the RPO, a different back-up regime should be implemented.
This entry was posted on Tuesday 14 June 2011